Overview #
The Parser Node is a powerful component of the AI Workflow Automation plugin that allows users to extract and process content from various document types. It utilizes the LlamaParse API to perform advanced document parsing, supporting multiple languages and customizable parsing instructions.
Features #
- Support for multiple input types (URL link or file upload)
- Ability to parse multiple documents in a single workflow
- Customizable parsing settings
- Support for various document formats (PDF, DOCX, etc.)
- Multi-language support
- Integration with LlamaParse API for advanced parsing capabilities
Node Configuration #
Input Type #
The Parser Node supports two types of input:
- Link: Allows users to provide a URL to a document for parsing.
- Upload: Enables users to upload one or more documents directly to the workflow.
Parser Settings #
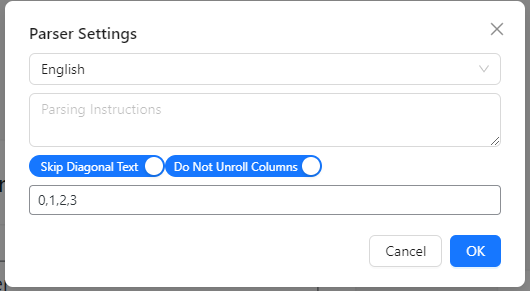
Users can customize the following parsing settings:
- Language: Select the primary language of the document(s) to be parsed. Supports a wide range of languages including English, Spanish, French, German, Chinese, and many more.
- Parsing Instructions: Provide specific instructions to guide the parsing process. This can be used to focus on particular types of information or structure in the document. This is basically a prompt that explains the document, and what you want from the parser. Use it, it’s very powerful.
- Skip Diagonal Text: When enabled, the parser will ignore text that appears diagonally in the document. This can be useful for excluding watermarks or other non-essential diagonal text.
- Do Not Unroll Columns: If enabled, the parser will maintain the column structure of the document. When disabled, it will attempt to present the content in a more linear fashion.
- Target Pages: Specify particular pages to be parsed. This can be a comma-separated list of page numbers or ranges (e.g., “1,3-5,7”).
Functionality #
- Document Upload:
- For the “Upload” input type, users can upload multiple documents.
- The node securely stores these documents within the WordPress media library.
- Parsing Process:
- The node sends each document to the LlamaParse API along with the specified parsing settings.
- It then polls the API for results, handling potential delays in processing large documents.
- Result Handling:
- Parsed content is stored within the node, allowing it to be used in subsequent nodes in the workflow.
- For multiple documents, the node maintains separate parsed content for each file.
- Error Handling:
- The node provides detailed error messages if parsing fails, aiding in troubleshooting.
- Common errors include API key issues, file access problems, or timeout errors for large documents.
Integration with Other Nodes #
- The parsed content can be used as input for other nodes in the workflow, such as AI Model nodes for further processing or analysis.
- Output nodes can be used to save or display the parsed content.
Example Use cases #
Link Input Type Examples #
- Competitive Analysis Dashboard
- Workflow:
- Parser Node: Accepts links to competitors’ product pages.
- AI Model Node: Extracts product features and pricing information.
- Sentiment Analysis Node: Analyzes customer reviews (if available) for sentiment.
- Research Node: Gathers additional market data related to the parsed products.
- Output Node: Saves the compiled data to a custom database table.
- Visualization Node: Creates charts and graphs from the saved data.
- Workflow:
- Automated Legal Document Review
- Workflow:
- Parser Node: Accepts a link to a legal document (e.g., contract, terms of service).
- AI Model Node: Identifies key clauses and legal terms.
- Condition Node: Checks for specific critical clauses.
- Human Input Node: If critical clauses are found, routes to legal team for review.
- Email Node: Sends notification to relevant parties based on the document content.
- Output Node: Saves a report of the document analysis to a specified location.
- Workflow:
Upload Input Type Examples #
- Multi-Document Research Analysis
- Workflow:
- Parser Node: Allows upload of multiple research papers or reports.
- AI Model Node: Extracts key findings, methodologies, and conclusions from each document.
- Summary Generator Node: Creates a consolidated summary of all parsed documents.
- Research Node: Performs additional web research to supplement the findings.
- Write Article Node: Generates a comprehensive literature review based on all inputs.
- Human Input Node: Routes the generated article for expert review.
- Post Node: Publishes the approved article on the website.
- Workflow:
- Automated Resume Screening and Candidate Ranking
- Workflow:
- Parser Node: Accepts uploads of multiple resumes.
- AI Model Node: Extracts relevant information (skills, experience, education) from each resume.
- Condition Node: Filters candidates based on minimum requirements.
- Sentiment Analysis Node: Analyzes the tone and language of the resumes.
- Research Node: Verifies online presence and gathers additional information about candidates.
- Output Node: Saves candidate data to a custom database table.
- Email Node: Sends interview invitations to top-ranked candidates.
- Workflow:
- Product Manual Consolidation and Chatbot Training
- Workflow:
- Use Case: A company wants to create an AI-powered customer support system based on their product manuals, FAQs, and technical documentation. Implementation:
- Upload all relevant company documents (manuals, FAQs, tech specs) to the Parser Node.
- Parse and store the content in a structured format.
- Use subsequent AI nodes to create a question-answering system that can quickly retrieve relevant information from the parsed documents.
- Integrate with a chatbot or customer support ticketing system to provide instant, accurate responses to customer queries.
- Workflow:
Best Practices #
- Ensure that the LlamaParse API key is correctly set in the plugin settings.
- For large documents, consider parsing specific pages to reduce processing time.
- Use clear and specific parsing instructions to improve the quality of extracted content.
- When parsing multiple documents, be mindful of potential increased processing time.
Limitations #
- The maximum file size and supported file types are determined by the LlamaParse API limitations.
- Processing time may vary based on document size and complexity.
- The accuracy of parsing can depend on the quality and format of the original document.
Troubleshooting #
- “Failed to start parsing job” error:
- Verify that the LlamaParse API key is correct and active.
- Check if the file is accessible and not corrupted.
- Timeout errors:
- For large documents, try parsing specific pages or splitting the document into smaller parts.
- Unexpected parsing results:
- Refine the parsing instructions.
- Ensure the correct language is selected.
Security Considerations #
- Uploaded documents are stored securely in the WordPress media library.
- API communication is conducted over HTTPS for data protection.
- User access to the Parser Node should be restricted to authorized personnel only.
- Consider that your data from your documents are being sent to Llamaindex for processing. Please review their Privacy Notice before using the service.


